Advanced segmentation techniques represent a significant leap forward in data analysis, moving beyond basic methods to unlock deeper insights from complex datasets. This evolution is driven by the increasing availability of large, high-dimensional data and the need for more nuanced understanding across diverse fields. From precision medicine leveraging medical imaging to targeted marketing campaigns maximizing customer engagement, the applications are vast and transformative.
This guide explores a range of sophisticated techniques, including clustering algorithms (k-means, hierarchical, DBSCAN), supervised learning methods (decision trees, support vector machines, neural networks), and dimensionality reduction approaches (PCA, t-SNE). We will delve into handling imbalanced datasets and evaluating model performance using relevant metrics. Finally, we will examine real-world applications across various industries, highlighting successful implementations and their impactful results.
Introduction to Advanced Segmentation Techniques
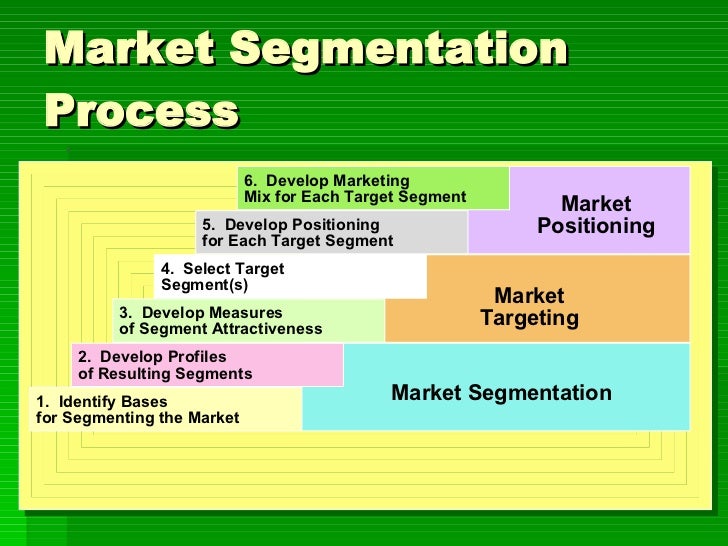
Segmentation, the practice of dividing a market into distinct groups of buyers with different needs, characteristics, or behaviors, has evolved significantly. Early methods relied on simple demographic variables like age and location. However, the increasing complexity of consumer behavior and the availability of vast amounts of data have driven the development of more sophisticated techniques. These advanced methods offer a far more nuanced understanding of customer segments, leading to more effective marketing strategies and improved business outcomes.
The need for advanced segmentation stems from several key factors. Firstly, the sheer volume and variety of data available today—from online browsing history and social media activity to purchase transactions and customer service interactions—demands more powerful analytical tools. Secondly, customers are increasingly diverse and their preferences are becoming more fragmented. Simple segmentation methods struggle to capture this granularity. Finally, businesses are under pressure to personalize their offerings and communications, requiring a deeper understanding of individual customer needs and motivations. This necessitates moving beyond basic demographic segmentation to more sophisticated approaches.
Examples of Advanced Segmentation Techniques
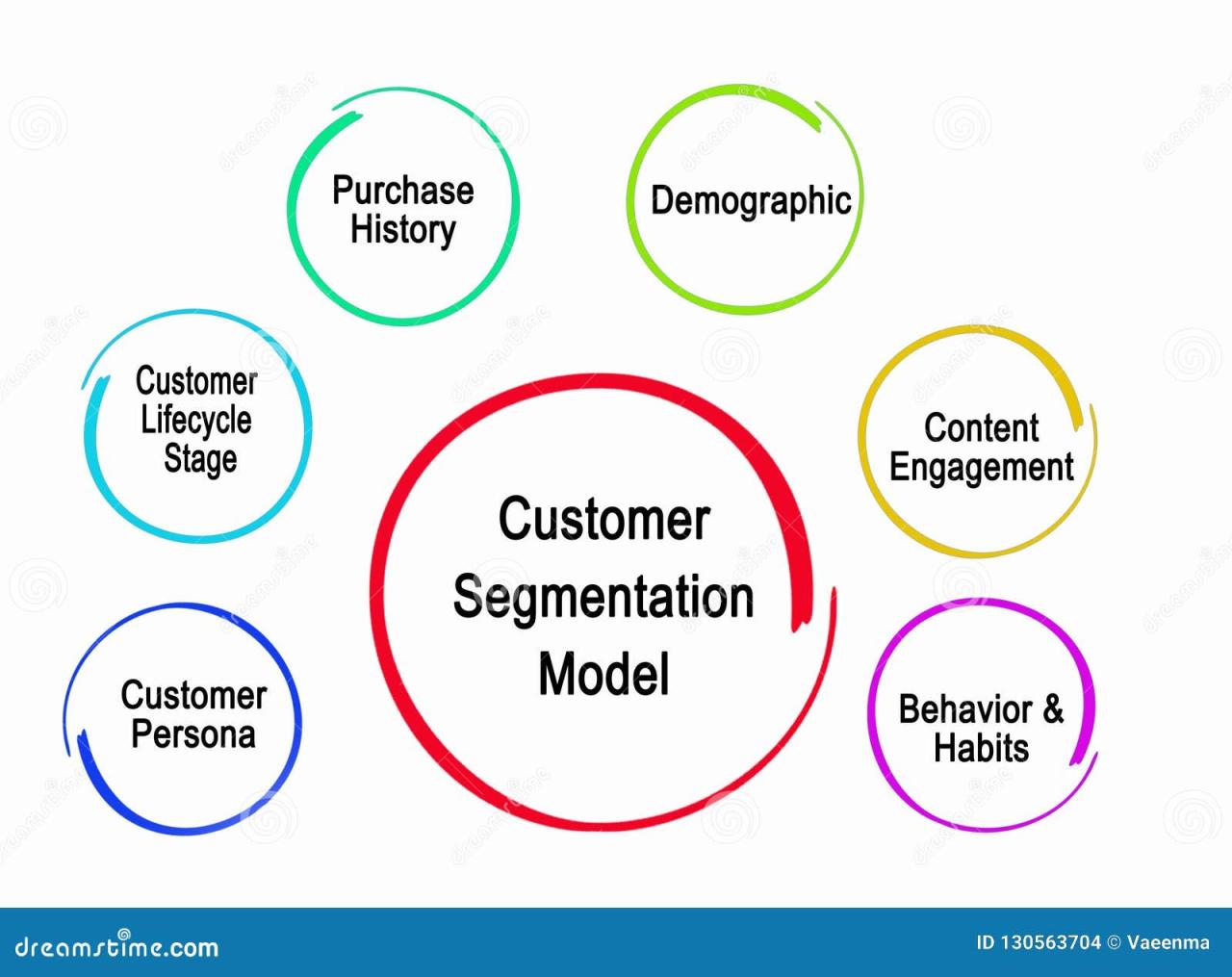
Advanced segmentation techniques leverage a variety of data sources and analytical methods to create more refined customer profiles. These methods go beyond simple demographic groupings to incorporate psychographic data (personality traits, values, lifestyle), behavioral data (purchase history, website activity), and even predictive modeling to anticipate future behavior. For instance, techniques like cluster analysis can identify groups of customers with similar characteristics, while machine learning algorithms can uncover hidden patterns and relationships within large datasets. This allows for a more granular and precise segmentation, leading to highly targeted marketing campaigns.
Industries Where Advanced Segmentation is Crucial
Advanced segmentation is particularly crucial in industries characterized by high customer diversity and complex purchasing behaviors. In the financial services sector, for example, understanding risk profiles and investment preferences requires sophisticated segmentation techniques to offer tailored products and services. Similarly, the healthcare industry utilizes advanced segmentation to target specific patient populations with tailored treatments and preventative care programs. E-commerce businesses rely on advanced segmentation to personalize product recommendations, optimize website experiences, and deliver targeted advertising. The competitive advantage gained from effectively understanding and targeting specific customer segments is significant in these and many other industries. For example, a streaming service might use advanced segmentation to tailor recommendations based on viewing history, genre preferences, and even viewing time, resulting in increased user engagement and retention. This is a far cry from the broad-brush approach of earlier segmentation methods.
Clustering Algorithms for Advanced Segmentation
Clustering algorithms are crucial for advanced segmentation techniques, enabling the grouping of data points based on inherent similarities. The choice of algorithm significantly impacts the effectiveness and efficiency of the segmentation process. Understanding the strengths and weaknesses of various algorithms is essential for selecting the most appropriate method for a given dataset and application.
K-means Clustering
K-means is a popular partitioning-based clustering algorithm. It aims to partition n observations into k clusters, where each observation belongs to the cluster with the nearest mean (centroid). The algorithm iteratively refines cluster assignments until convergence. K-means is relatively simple to implement and computationally efficient for large datasets, making it scalable. However, its performance is heavily dependent on the initial placement of centroids, and it struggles with non-spherical clusters or clusters with varying densities. Furthermore, the user needs to pre-define the number of clusters (k), which can be challenging without prior domain knowledge. Interpretability is generally straightforward, as clusters are defined by their centroids.
Hierarchical Clustering
Hierarchical clustering builds a hierarchy of clusters, represented as a dendrogram. There are two main approaches: agglomerative (bottom-up) and divisive (top-down). Agglomerative clustering starts with each data point as a separate cluster and iteratively merges the closest clusters until a single cluster remains. Divisive clustering starts with a single cluster and recursively splits it until each data point forms its own cluster. Hierarchical clustering offers a visual representation of the clustering process, providing insights into the relationships between clusters. However, it can be computationally expensive for large datasets, particularly agglomerative methods. The choice of distance metric and linkage criterion also significantly impacts the results. Interpretability is relatively high due to the hierarchical structure, but the optimal number of clusters often requires subjective judgment based on the dendrogram.
DBSCAN Clustering
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a density-based clustering algorithm that groups data points based on their density. It identifies clusters as dense regions separated by low-density regions. DBSCAN is robust to outliers and can discover clusters of arbitrary shapes, unlike k-means. It automatically determines the number of clusters, eliminating the need for pre-defined k. However, DBSCAN is sensitive to the choice of parameters (epsilon and minimum points) and can struggle with clusters of varying densities. Scalability can be a concern for very high-dimensional data. Interpretability can be less straightforward than k-means or hierarchical clustering, as cluster membership is not based on a simple distance metric.
Comparison of Clustering Algorithms
The following table summarizes the key characteristics of the three algorithms:
| Algorithm | Scalability | Interpretability | Accuracy | Computational Cost | Suitable Data Types |
|---|---|---|---|---|---|
| K-means | High | High | Moderate (sensitive to initial conditions and cluster shape) | Low | Numerical data |
| Hierarchical | Low (agglomerative) | High | Moderate (sensitive to distance metric and linkage) | High (agglomerative) | Numerical data |
| DBSCAN | Moderate | Moderate | High (robust to outliers and non-spherical clusters) | Moderate | Numerical data |
Supervised Segmentation Methods

Supervised segmentation leverages labeled data to train a model that can accurately classify pixels or regions within an image into predefined categories. Unlike unsupervised methods, which discover patterns in unlabeled data, supervised approaches require a dataset where each pixel or region is already assigned to a specific class. This allows for more precise and targeted segmentation, particularly when dealing with complex or nuanced image data.
Supervised learning techniques offer a powerful approach to image segmentation, providing a framework for building models that learn intricate relationships between image features and class labels. This approach is particularly beneficial when dealing with datasets where the classes of interest are well-defined and a significant amount of labeled training data is available. The accuracy of the segmentation heavily relies on the quality of the training data and the careful selection and engineering of relevant features.
Applying Supervised Learning Techniques
Decision trees, support vector machines (SVMs), and neural networks (particularly convolutional neural networks or CNNs) are commonly employed in supervised image segmentation. Decision trees recursively partition the feature space to create a tree-like structure that classifies pixels based on a series of decision rules. SVMs aim to find an optimal hyperplane that maximally separates different classes in the feature space. Neural networks, especially CNNs, excel at learning complex, hierarchical representations of image data, allowing for highly accurate segmentation even in the presence of noise or variations in image appearance. The choice of algorithm depends on factors such as the complexity of the data, the size of the dataset, and the computational resources available. For example, CNNs are often preferred for large, high-resolution images due to their ability to learn intricate features automatically.
Feature Engineering for Improved Accuracy
Feature engineering plays a crucial role in improving the accuracy of supervised segmentation models. Well-crafted features provide the model with informative inputs, enabling it to learn more effective decision boundaries. Relevant features can include color histograms, texture features (e.g., Gabor filters, Haralick features), edge information, and shape descriptors. Moreover, advanced features can be extracted using techniques like wavelet transforms or deep learning-based feature extractors. The process of feature selection is also important to avoid overfitting and improve model generalizability. Dimensionality reduction techniques like Principal Component Analysis (PCA) can be used to reduce the number of features while retaining most of the relevant information.
Hypothetical Scenario: Satellite Imagery Segmentation
Consider a scenario where we aim to segment satellite imagery to identify different land cover types (e.g., urban areas, forests, water bodies). We would use a labeled dataset of satellite images, where each pixel is manually annotated with its corresponding land cover class. A Convolutional Neural Network (CNN), such as U-Net, would be a suitable choice due to its effectiveness in handling spatial information and its ability to learn complex feature representations. The CNN would be trained on a subset of the labeled data, and its performance would be evaluated on a held-out test set using metrics such as overall accuracy, precision, recall, and the F1-score. These metrics provide a comprehensive assessment of the model’s ability to accurately identify different land cover types. For example, a high precision for “urban areas” would indicate that the model rarely misclassifies non-urban pixels as urban, while high recall would mean that most actual urban pixels are correctly identified. A low F1-score for “forests” might suggest the need for further feature engineering or model refinement to improve the model’s ability to distinguish forests from similar land cover types.
Dimensionality Reduction Techniques in Segmentation
High-dimensional data, often encountered in advanced segmentation tasks, presents significant challenges. Computational costs increase exponentially, and the so-called “curse of dimensionality” can lead to poor model performance and difficulties in interpreting results. Dimensionality reduction techniques offer a powerful solution by transforming the data into a lower-dimensional space while preserving essential information relevant to segmentation. This process improves efficiency, enhances performance, and facilitates a clearer understanding of the segmented groups.
Dimensionality reduction methods effectively mitigate the challenges posed by high-dimensional data in segmentation. By reducing the number of features while retaining crucial variance, these techniques streamline computations, prevent overfitting, and improve the overall accuracy and speed of segmentation algorithms. The choice of technique depends heavily on the dataset and the specific goals of the segmentation process.
Principal Component Analysis (PCA) in Segmentation
Principal Component Analysis (PCA) is a widely used linear dimensionality reduction technique. It identifies principal components, which are new uncorrelated variables that capture the maximum variance in the data. By projecting the data onto the first few principal components (those explaining the most variance), the dimensionality is reduced while retaining most of the relevant information. In segmentation, PCA can significantly speed up clustering algorithms like k-means by reducing the computational burden associated with high-dimensional feature spaces. For instance, segmenting satellite imagery with numerous spectral bands could benefit from PCA, reducing the number of input features for a clustering algorithm without substantially losing information about land cover types. The resulting segmentation would be more efficient and potentially more accurate due to the reduced noise in the lower-dimensional space.
t-distributed Stochastic Neighbor Embedding (t-SNE) in Segmentation
t-SNE is a non-linear dimensionality reduction technique particularly effective in visualizing high-dimensional data. Unlike PCA, t-SNE focuses on preserving the local neighborhood structure of the data points. This means that points that are close together in the high-dimensional space tend to remain close in the low-dimensional representation. This characteristic makes t-SNE particularly useful for visualizing the results of segmentation, allowing for easier interpretation and identification of distinct clusters. Consider a gene expression dataset where each sample is characterized by thousands of genes. Applying t-SNE allows researchers to visualize the samples in a 2D or 3D space, making it easier to identify groups of samples with similar expression patterns, which would correspond to different cell types after segmentation. This visual representation significantly enhances the interpretability of the segmentation results.
Comparison of PCA and t-SNE for Segmentation
PCA and t-SNE serve different purposes in the context of segmentation. PCA is primarily used for dimensionality reduction to improve the efficiency and performance of segmentation algorithms, while t-SNE is mainly employed for visualization and interpretation of the results. PCA is computationally faster and more suitable for large datasets, while t-SNE is better at preserving local neighborhood structures, leading to more informative visualizations, especially for complex datasets with non-linear relationships between features. The choice between these techniques often depends on whether the priority is computational efficiency or visual interpretability of the segmentation results. A common approach is to use PCA for preprocessing to reduce dimensionality before applying a segmentation algorithm and then use t-SNE to visualize the resulting clusters.
Enhancing Interpretability of Segmentation Results with Dimensionality Reduction
Dimensionality reduction techniques significantly improve the interpretability of segmentation results, especially in high-dimensional settings. By reducing the number of features, these techniques make it easier to understand the characteristics that define each segment. For example, in customer segmentation based on purchase history, applying PCA could reveal the principal components representing spending habits, demographics, or product preferences. These principal components, rather than thousands of individual purchase records, provide a more concise and insightful description of each customer segment. Similarly, in medical image segmentation, dimensionality reduction can highlight the key features distinguishing different tissue types, facilitating a more accurate and understandable diagnosis.
Handling Imbalanced Datasets in Advanced Segmentation: Advanced Segmentation Techniques

Imbalanced datasets, where one class significantly outnumbers others, pose a significant challenge in advanced segmentation tasks. This imbalance can lead to biased models that perform poorly on the minority classes, which are often the most clinically or practically relevant. For example, in medical image segmentation, identifying cancerous cells (minority class) within a large volume of healthy tissue (majority class) requires careful consideration of this imbalance to avoid misdiagnosis. Effective strategies are crucial to ensure accurate and reliable segmentation results.
Addressing class imbalance in segmentation requires a multifaceted approach. Techniques generally fall into two categories: data-level approaches that modify the dataset itself and algorithm-level approaches that adjust the learning process. Choosing the most appropriate technique depends on the specific characteristics of the dataset and the segmentation task.
Resampling Techniques, Advanced segmentation techniques
Resampling methods aim to balance class proportions by either oversampling the minority class or undersampling the majority class. Oversampling techniques, such as SMOTE (Synthetic Minority Over-sampling Technique), create synthetic samples of the minority class based on existing data points. This helps increase the representation of the under-represented classes without simply duplicating existing data. Undersampling techniques, like random undersampling, randomly remove samples from the majority class to reduce its dominance. However, random undersampling can lead to information loss if not carefully applied. A more sophisticated approach is Tomek links, which removes majority class samples that form Tomek links with minority class samples, effectively cleaning up the decision boundary. The choice between oversampling and undersampling, or a combination of both, often depends on the size and characteristics of the dataset. For instance, if the minority class has very few samples, oversampling might be preferred to avoid losing valuable information. Conversely, if the majority class is overwhelmingly large, undersampling might be more computationally efficient.
Cost-Sensitive Learning
Cost-sensitive learning modifies the learning algorithm to assign different misclassification costs to different classes. This approach directly addresses the imbalance by penalizing misclassifications of the minority class more heavily than those of the majority class. This can be achieved by adjusting class weights in the loss function, making the model more sensitive to errors in the minority class. For example, in a support vector machine (SVM), we can assign a higher cost to misclassifying a cancerous cell (minority class) compared to misclassifying a healthy cell (majority class). This encourages the model to focus more on accurately identifying the minority class, even if it means sacrificing some accuracy on the majority class.
Best Practices for Handling Imbalanced Data in Advanced Segmentation
Effective handling of imbalanced datasets requires careful planning and execution. The following best practices should be considered:
- Thorough Data Analysis: Before applying any technique, carefully analyze the class distribution and explore potential reasons for the imbalance. This includes visualizing the data and identifying potential biases.
- Appropriate Evaluation Metrics: Accuracy alone is insufficient for evaluating models trained on imbalanced data. Utilize metrics such as precision, recall, F1-score, and AUC-ROC to provide a more comprehensive assessment of performance across all classes.
- Cross-Validation: Employ stratified k-fold cross-validation to ensure that the class distribution is maintained across all folds. This prevents bias in model evaluation.
- Ensemble Methods: Combining multiple models trained with different resampling or cost-sensitive techniques can improve overall performance and robustness.
- Iterative Approach: Experiment with different resampling and cost-sensitive techniques, evaluating their performance using appropriate metrics. This iterative process allows for refinement and optimization of the chosen strategy.
Evaluating the Performance of Advanced Segmentation Techniques
Effective evaluation is crucial for selecting the best segmentation model for a given task. Different metrics provide different perspectives on model performance, and the choice of metric should align with the specific goals of the segmentation. Visualizations further enhance our understanding by providing a direct comparison between the segmented output and the ground truth.
Segmentation Metrics
Several metrics are commonly used to evaluate the performance of segmentation models. These metrics quantify the overlap between the predicted segmentation and the ground truth segmentation, providing a numerical measure of the model’s accuracy. The choice of which metric(s) to prioritize depends on the relative importance of correctly identifying positive instances (true positives) versus avoiding incorrectly identifying negative instances as positive (false positives).
- Precision: Precision measures the proportion of correctly identified positive instances (true positives) out of all instances predicted as positive (true positives + false positives). A high precision indicates that the model rarely makes false positive predictions. For example, in medical image segmentation, high precision is crucial to avoid misdiagnosing healthy tissue as cancerous. The formula for precision is:
Precision = True Positives / (True Positives + False Positives)
- Recall (Sensitivity): Recall measures the proportion of correctly identified positive instances (true positives) out of all actual positive instances (true positives + false negatives). High recall indicates that the model effectively identifies most of the positive instances. In the same medical imaging scenario, high recall is crucial to ensure that no cancerous tissue is missed. The formula for recall is:
Recall = True Positives / (True Positives + False Negatives)
- F1-Score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of both precision and recall, useful when both are important. A high F1-score suggests a good balance between minimizing false positives and false negatives. The formula for the F1-score is:
F1-Score = 2 * (Precision * Recall) / (Precision + Recall)
- Silhouette Score: The silhouette score is particularly relevant for clustering-based segmentation methods. It measures how similar a data point is to its own cluster compared to other clusters. A score closer to 1 indicates well-separated clusters, suggesting good segmentation quality. A score close to -1 indicates that data points might be assigned to the wrong cluster. A score around 0 suggests overlapping clusters, indicating potential issues with the segmentation.
Interpreting Segmentation Metrics and Choosing Appropriate Metrics
The selection of appropriate metrics depends heavily on the application. For example, in a medical image segmentation task where missing a cancerous region is far more critical than incorrectly identifying a healthy region as cancerous, recall should be prioritized over precision. Conversely, in spam detection, where incorrectly classifying a legitimate email as spam is more costly, precision would be more important. A balanced approach, using the F1-score, is often suitable when the costs of false positives and false negatives are comparable. The silhouette score is valuable when evaluating the quality of clusters produced by a segmentation algorithm.
Visualization Techniques for Segmentation Evaluation
Visualizations are invaluable for assessing the quality of a segmentation model. They allow for a quick, intuitive understanding of the model’s performance that complements the numerical metrics.
- Overlay of Predicted and Ground Truth Segmentations: This visualization directly compares the model’s output with the true segmentation. Different colors can represent different segments, allowing for a visual assessment of the overlap and discrepancies. For instance, a transparent overlay of the predicted segmentation on the ground truth image allows for easy comparison and identification of errors. Areas of significant mismatch would immediately stand out.
- Confusion Matrix: A confusion matrix visually represents the counts of true positives, true negatives, false positives, and false negatives. This allows for a clear understanding of the types of errors made by the model and helps in identifying areas for improvement. A well-performing model will have high counts along the diagonal of the matrix.
- Precision-Recall Curve: This curve plots precision against recall for different thresholds. The area under the curve (AUC) provides a summary measure of the model’s performance across different thresholds. A higher AUC indicates better performance. This visualization helps to understand the trade-off between precision and recall.
Advanced Segmentation Applications
Advanced segmentation techniques, as discussed previously, offer powerful tools for analyzing complex datasets across numerous fields. Their ability to identify meaningful subgroups within data allows for targeted interventions, improved predictions, and a deeper understanding of underlying patterns. This section explores several key applications, highlighting successful implementations and their impact.
The application of advanced segmentation techniques is widespread, impacting various sectors significantly. The choice of technique depends heavily on the nature of the data and the specific goals of the segmentation process. For instance, medical imaging relies on different approaches compared to customer relationship management (CRM) or fraud detection systems. The common thread is the ability to extract meaningful insights from complex data to achieve specific business objectives.
Medical Imaging Analysis
Advanced segmentation plays a crucial role in medical image analysis, enabling precise identification of organs, tumors, and other anatomical structures. For example, in oncology, accurate segmentation of tumor boundaries from MRI or CT scans is vital for treatment planning and monitoring response to therapy. Techniques like level set methods, active contours, and deep learning-based segmentation models (e.g., U-Net) are frequently employed. Successful implementation leads to improved diagnostic accuracy, personalized treatment strategies, and better patient outcomes. A study published in the journal *Radiology* demonstrated that a deep learning-based segmentation model achieved superior accuracy in identifying lung nodules compared to traditional manual segmentation, reducing the time required for analysis and improving detection rates.
Customer Relationship Management (CRM)
In CRM, advanced segmentation allows businesses to categorize customers based on demographics, purchasing behavior, and engagement patterns. This enables targeted marketing campaigns, personalized recommendations, and improved customer service. Clustering algorithms like k-means and hierarchical clustering, along with techniques like DBSCAN for identifying clusters of varying densities, are frequently used. A successful case study involves a major e-commerce company that segmented its customer base using a combination of purchase history and browsing behavior. This allowed them to personalize email marketing campaigns, resulting in a significant increase in conversion rates and customer lifetime value.
Fraud Detection
Advanced segmentation is crucial in fraud detection systems, helping identify suspicious patterns and transactions. Anomaly detection techniques, combined with supervised learning methods, are commonly used to segment transactions into fraudulent and non-fraudulent groups. Isolation Forest and One-Class SVM are examples of algorithms frequently employed. A financial institution successfully implemented a fraud detection system using anomaly detection techniques, resulting in a significant reduction in fraudulent transactions and a substantial cost saving. The system identified subtle patterns indicative of fraudulent activity that were missed by traditional rule-based systems.
| Application Area | Segmentation Technique | Key Results | Illustrative Example |
|---|---|---|---|
| Medical Imaging (Tumor Segmentation) | U-Net (Deep Learning) | Improved diagnostic accuracy, faster analysis | A study showing improved lung nodule detection. |
| Customer Relationship Management | K-means Clustering | Increased conversion rates, higher customer lifetime value | E-commerce company personalizing email campaigns. |
| Fraud Detection | Isolation Forest (Anomaly Detection) | Reduced fraudulent transactions, cost savings | Financial institution identifying fraudulent patterns. |
Ending Remarks
Mastering advanced segmentation techniques empowers analysts and researchers to extract meaningful patterns and predictions from intricate data landscapes. By understanding the strengths and limitations of various algorithms, and employing appropriate evaluation metrics, we can build robust and insightful models. The applications explored throughout this guide demonstrate the transformative potential of these methods across diverse fields, underscoring their importance in today’s data-driven world. Further exploration and refinement of these techniques will undoubtedly continue to shape future advancements in data analysis and decision-making.
Advanced segmentation techniques are crucial for creating realistic simulations, particularly in areas requiring precise object recognition and tracking. Consider the complexities involved in developing a game like the Permainan tenis meja virtual , where accurate ball trajectory prediction relies heavily on effective segmentation of the playing area and the objects within it. These same techniques can then be applied to other complex simulations demanding high-fidelity object separation and analysis.
Advanced segmentation techniques are crucial for effective marketing campaigns. Understanding the latest consumer behaviors is key to their success, and staying updated on these trends is vital; you can find insightful analysis in Marketing trend reports. This knowledge directly informs the refinement and optimization of advanced segmentation strategies, ensuring your targeting is precise and impactful.